





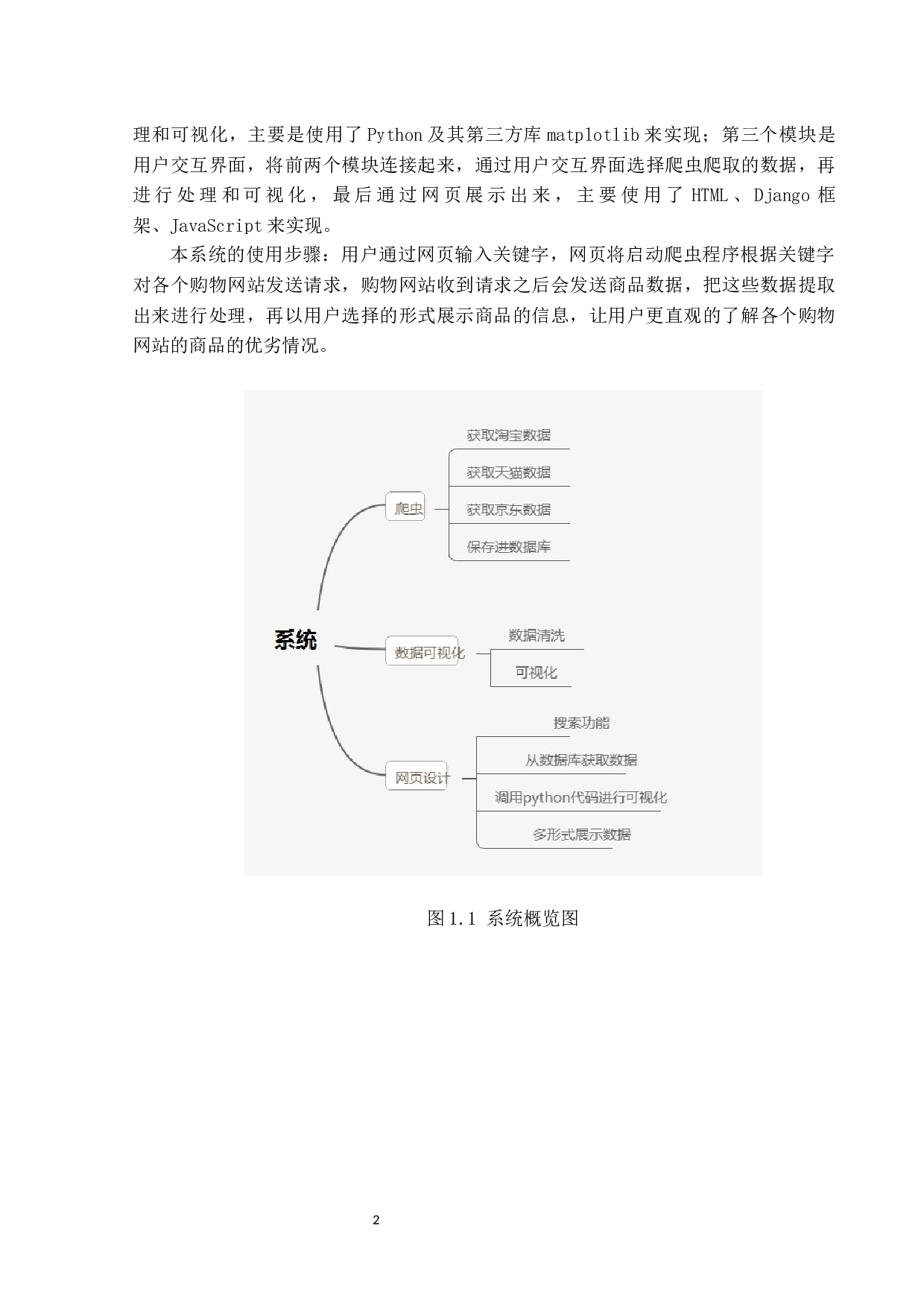



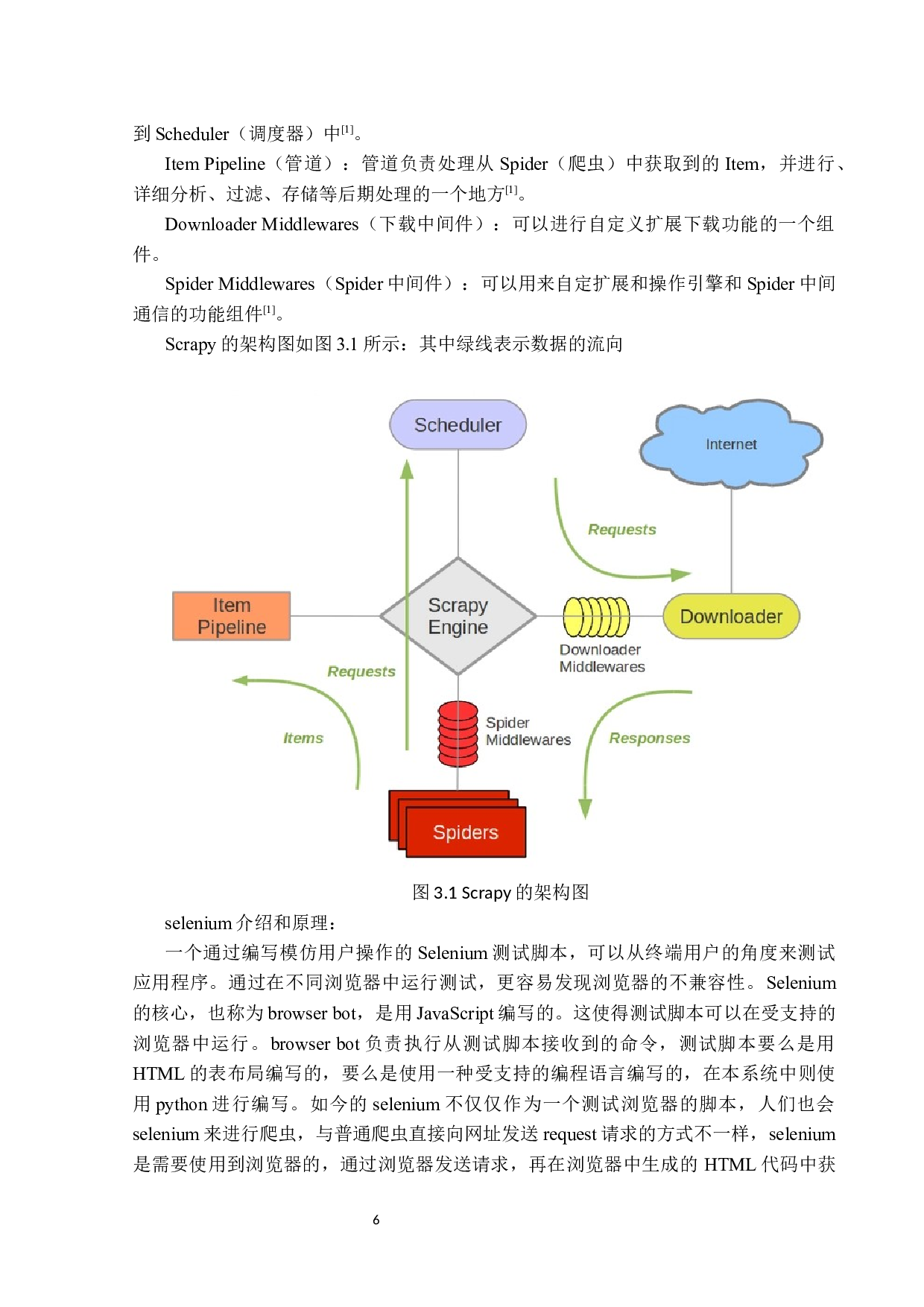
基于
scrapy
的通用爬虫系统的设计与实现
摘 要
网络爬虫
,是
一个自动提取网页的程序
。
随着
网络
的迅速发展,
万维网
成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战
,而爬虫可以使我们更加快速便捷的获取我们需要的数据和信息
。
对于当今
许多人都喜欢在网上购物而网络购物商品种类繁多
,
让人看了眼花缭乱
,
我们可以通过爬虫获取网络商品的数据,然后对这些数据进行一些处理,让我们更直观的看到这些商品的优缺点
,
让我们更方便地进行网上
购物。
本文所介绍的基于
scrapy
的通用爬虫系统就是用于爬
基于scrapy的通用爬虫系统的设计与实现-11889字.docx