







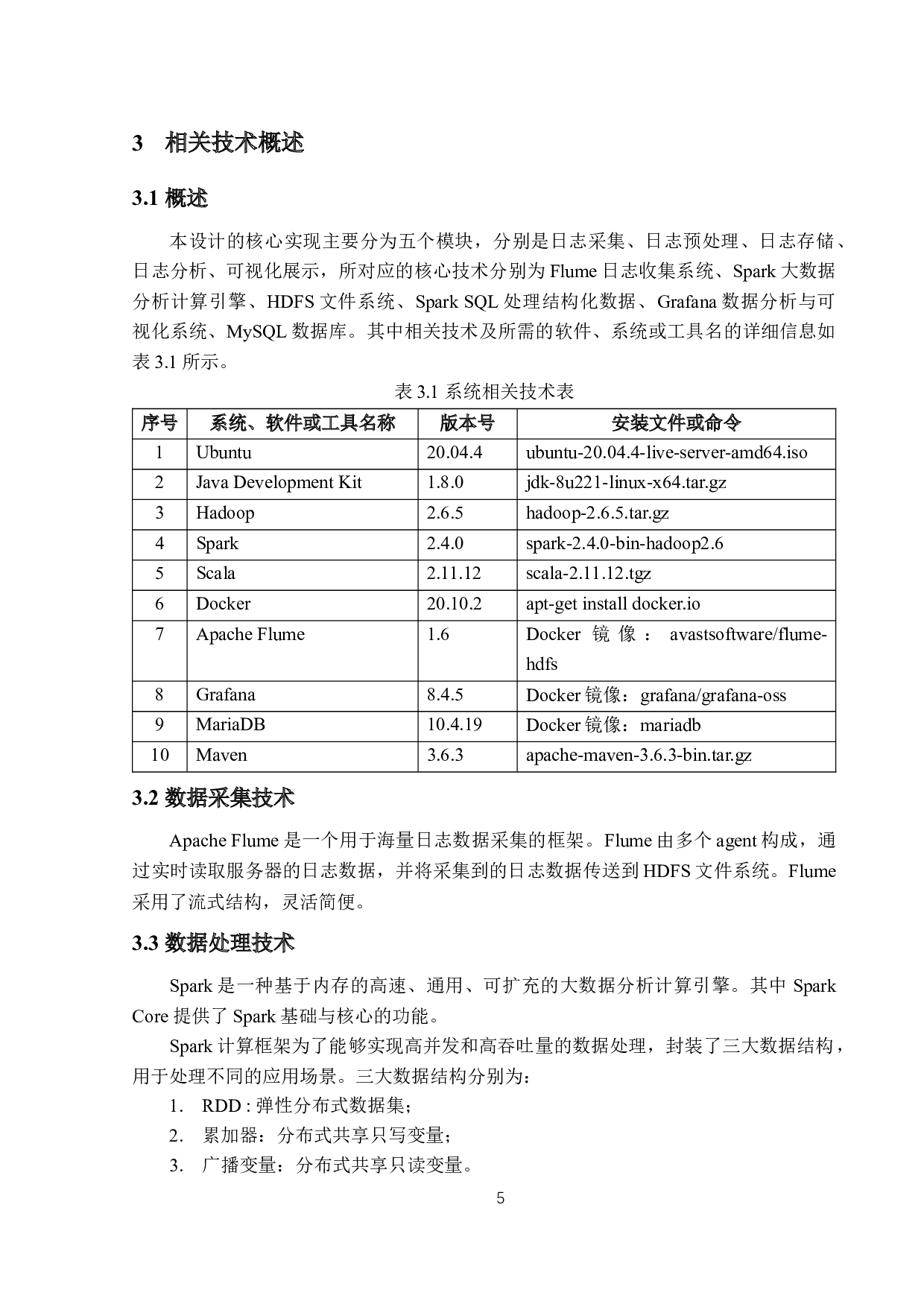

基于
Hadoop
和
Spark
的
WEB
服务器访问日志分析系统的设计与实现
摘
要
随着互联网用户
数量
的快速增长,大型
网
站
产生的
WEB
日志
总量也
呈
指数
级
上升
,
而传统单机系统
的
计算及存储性能
的不足
则
突
现
出来,即无法高效处理
、
分析
海量日志数据
。
因此
,
分布式存储计算成为了解决海量
WEB
日志的关键技术。如何有效
地
从海量的日志信息中挖掘出价值
也成为急需解决的
主要
问题。
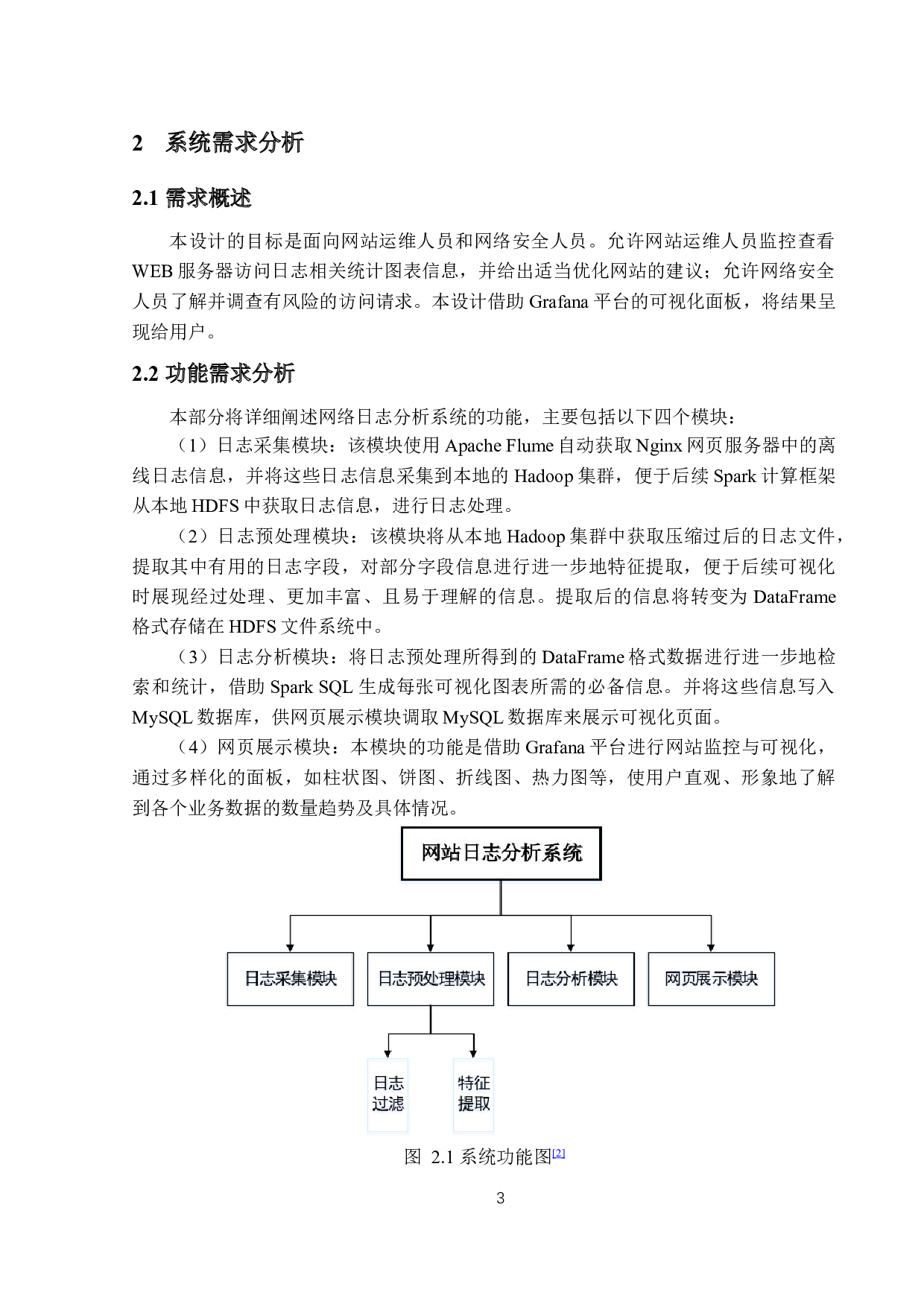
本
设计
包括
日志采集、日志预处理、日志分析、
Grafana
可视化展示等四个
功能
模块
,
通过搭建
Spark
yarn
分布式
集群,使
基于Hadoop和Spark的WEB服务器访问日志分析系统的设计与实现-11829字.docx